菜单
首页财产ai正文 方才,英伟达革了本身的命 本周四英伟达研究团队提交 AVO 研究,构建新型进化变异算子,经 7 天自立演化,于 GPU 上优化 MHA 内核,机能超基准,优化可迁徙,为主动化软件优化指路。 2026-03-26 13:09 ·呆板之心计心情器之心 AI投资人解读· 英伟达新研究AVO构建新型进化变异算子,用智能体代替固定变异等要领。于留意力机制事情负载中,智能体可持续搜刮7天逾越人类专家。运用在MHA内核,机能逾越cuDNN 3.5%、FlashAttention-4 10.5%,优化技能能迁徙至GQA。 · 行业竞争激烈,其他团队可能快速跟进研究结果技能成长迅速,若呈现更优技能,AVO可能被替换。 总结:AVO揭示强盛机能与泛化能力,为主动化软件体系优化提供新思绪,但面对行业竞争与技能更新危害,需连续存眷其成长动态和行业趋向。内容由AI天生,仅供参考
这应该是今天方才出炉的、最炸裂的文章。
于许多算子开发的微信群组,已经经掀起了轩然年夜波。
「这也许是超人类智能于软件范畴的真正初次展露。」英伟达许冰方才于 X 上发出了云云断言。他所评论的,恰是他与 Terry Chen 及 Zhifan Ye 为配合一作的一项英伟达新研究AVO。

于本周四方才提交到 arXiv 上的这项研究中,英伟达构建了Agentic Variation Operator(AVO),这是一类新型进化变异算子,它用自立编码智能体代替了经典进化搜刮中固定的变异、交织及人工设计的开导式要领,并取患了相称震撼的现实体现。
许冰暗示:「于一些颠末高度优化的留意力机制事情负载中,智能体于没有人工干涉干与的环境下,便可于优化轮回中持续搜刮 7 天,从而逾越险些所有人类 GPU 专家。」——AVO 的云云体现可能会让很多内核/DSL 瑟瑟颤栗。

成心思的是,于 X 推文中,许冰还有分享说一年半以前他与 Terry Chen 刚最先于英伟达研究智能体编程时,他们还有不懂 GPU 编程,「以是从一最先咱们就致力在开发彻底主动化、无需人工干涉干与的体系。」他们称之为「盲编程(blind coding)」。
「于已往一年半的时间里,咱们两人于两个智能系统统中开发了四代智能体。从第二代最先,这些智能体栈就最先自我演化。此刻每一个智能体的代码行数都约为 10 万行(非空代码)。」
他还有重点夸大了 AVO 暗地里的庞大意义:「我敢赌钱:盲编程是软件工程的将来。人类认知能力是瓶颈。」
下面咱们就来具体看看这篇或者将开启「盲编程」新时代的论文毕竟做出了甚么孝敬。

论文标题:AVO: Agentic Variation Operators for Autonomous Evolutionary Search
论文地址:https://arxiv.org/abs/2603.24517v1
年夜语言模子已经成为进化搜刮(Evolutionary Search)中的强盛组件,它以进修代码天生代替了手工设计的变异算子。于这些体系中,LLM 按照选定的父代天生候选解,而凡是基在开导式的框架则卖力父代采样、评估及种群治理。这类组合于数学优化及算法发明范畴取患了显著结果,包括 FunSearch 及 AlphaEvolve 等旗舰体系。
然而,将 LLM 限定于预设流程中的候选解天生功效从底子上限定了其发明能力:每一次挪用仅孕育发生一个输出,没法自动查阅参考资料、测试其更改、解读反馈或者于提交候选方案前批改方案。对于在那些已经颠末*人工调优、需要深度迭代工程才能进一步改良的实现,这类限定尤为凸起。
研究者针对于留意力机制配景下的这一问题举行了研究。留意力机制是 Transformer 架构的焦点算子,也是优化最密集的 GPU 算子之一。FlashAttention 系列 及英伟达的 cuDNN 库已经将历代 GPU 的留意力吞吐量推向硬件极限;于最新的 Blackwell 架构上,FlashAttention-4 (FA4) 及 cuDNN 均需要数月的人工优化。若要逾越这些实现,需要与开发情况举行连续、迭代的交互:研究硬件文档、阐发阐发器(Profiler)输出以辨认瓶颈、实现并测试候选优化方案、诊断准确性妨碍,并按照堆集的经验批改计谋。
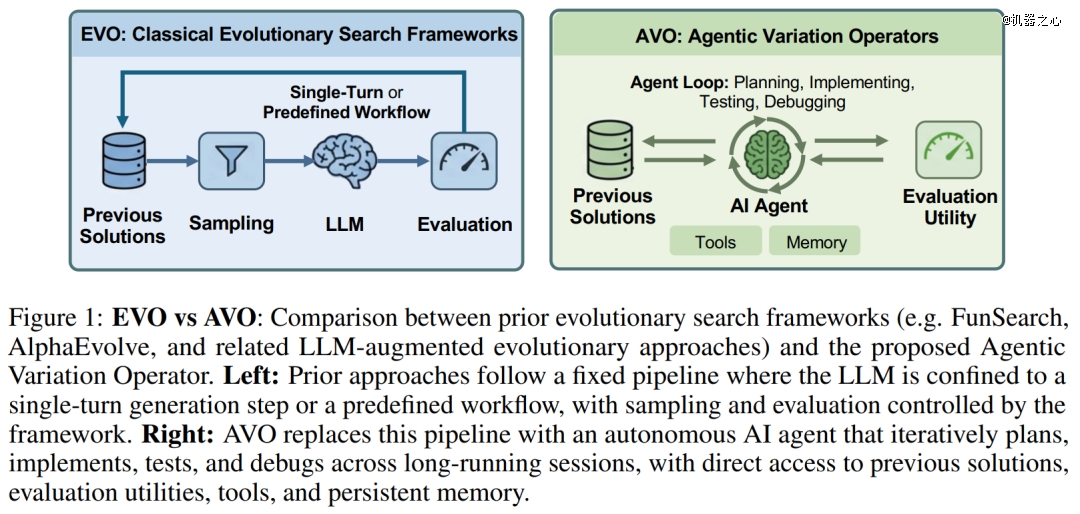
深度智能体(Deep Agents)的最新进展注解,联合了计划、长期内存及东西利用能力的 LLM 可以自立处置惩罚此类多步工程事情流,运用规模涵盖从解决繁杂的 GitHub 问题到天生要害深度进修软件。这促使 LLM 于演化搜刮中饰演一种大相径庭的脚色:与其将其限定于固定流水线内,不如将深度智能体晋升为变异算子自己。
为此,英伟达提出了智能体式变异算子(Agentic Variation Operators, AVO)。于这类模式下,一个自导向的代码代办署理代替了以往基在单轮 LLM 或者固定事情流体系中的变异及交织历程。AVO 智能体拥有拜候所有先前方案、特定范畴常识库及评估东西的权限。它能自立决议查阅内容、修改对于象以和评估机会,从而实此刻长周期内的连续改良。
为了验证其有用性,英伟达将 AVO 运用在NVIDIA Blackwell B200 GPU上的多头留意力(MHA)内核,并直接与专家优化的 cuDNN 及 FlashAttention-4 内核举行对于比。于无需人工干涉干与、长达 7 天的持续自立演化中,智能体摸索了跨越 500 个优化标的目的,演化出 40 个内核版本。终极天生的 MHA 内核于 BF16 精度下到达了最高1668 TFLOPS的吞吐量,于测试配置中别离逾越 cuDNN 高达3.5%,逾越 FlashAttention-4 高达10.5%。
英伟达对于智能体发明的优化方案举行阐发后发明,这些优化涵盖了内核设计的多个层面,包括寄放器分配、指令流水线调理及负载漫衍,反应了真实的硬件级推理。试验注解,于 MHA 上发明的优化技能能有用迁徙至分组查询留意力(GQA):智能体仅需 30 分钟的分外自立适配,便可完成演化版 MHA 内查对 GQA 的撑持,其机能比拟 cuDNN 晋升高达 7.0%,比拟 FlashAttention-4 晋升 9.3%。
该研究的重要孝敬以下:
提出代办署理式变异算子(AVO):这是一类新型的演化变异算子,将智能体从纯真的候选天生器晋升为变异算子。智能体经由过程与情况的迭代交互,自立摸索范畴常识、实行修改并验证成果。
实现 SOTA 机能:于 NVIDIA B200 GPU 上,研究者于基准测试配置中实现了最*的 MHA 吞吐量,到达 1668 TFLOPS,机能逾越 cuDNN 高达 3.5%,逾越 FlashAttention-4 高达 10.5%。此外,他们证实了这些优化可以轻松迁徙至 GQA,仅需 30 分钟的自立演化便可得到显著机能增益。
微架构优化阐发:研究者对于智能体于基准测试设置下发明的微架构优化举行了具体阐发,注解代办署理举行的是真实的硬件级推理,而非表层的代码变换。
离别流水线
AI 智能体成为真实的「进化操盘手」
于传统的基在 LLM 的进化搜刮框架中,模子往往被困于固定的流水线里,仅仅充任候选代码的天生器。它们每一次挪用只能输出一次成果,没法自动查阅参考资料、测试代码、理解反馈或者于终极提交前批改计谋。对于在需要深度、重复迭代的*硬件优化使命来讲,这类限定尤为致命。
AVO 打破了这一局限,将「变异算子」实例化为一个自我驱动的智能体轮回。这个 AI 智能体可以自由查阅以前的代码版本记载、挪用范畴专属的常识库(如 CUDA 编程指南及 PTX 架构文档),并按照履行反馈来自动提出、修复、批判及验证代码修改。
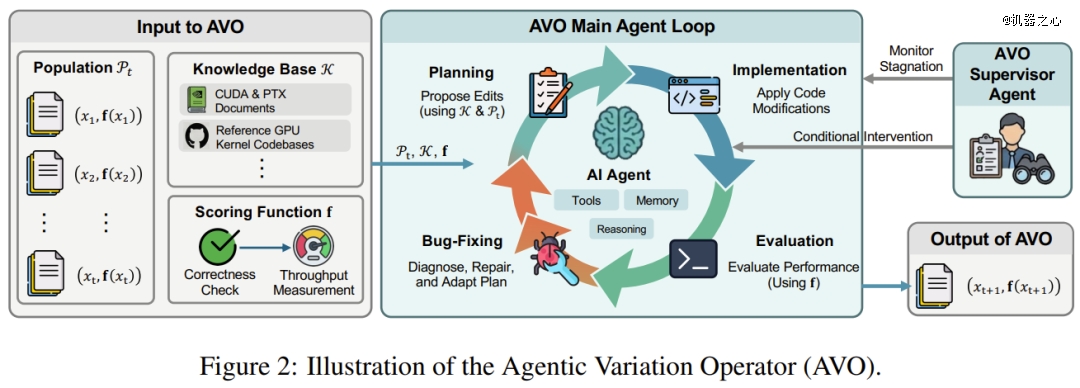
简而言之,AVO 将 AI 从被动的「代码天生器」晋升为了把握全局的「进化操盘手」。
7 天自立运转
于 Blackwell 架构上击败*基准
研究团队将 AVO 部署于一项*挑战性的使命上:于 NVIDIA Blackwell (B200) GPU 上优化多头留意力(Multi-head Attention,简称 MHA)焦点代码。留意力机制是今朝 Transformer 架构的焦点,也是 AI 芯片上被优化患上最*的计较方针之一。
于彻底没有人类干涉干与的环境下,AVO 智能体持续自立运行了 7 天。
于这 7 天里,智能体于后台摸索了跨越 500 个优化标的目的,并终极提交了 40 个有用迭代版本。终极,它天生的 MHA 焦点于 BF16 精度下实现了高达 1668 TFLOPS 的吞吐量。
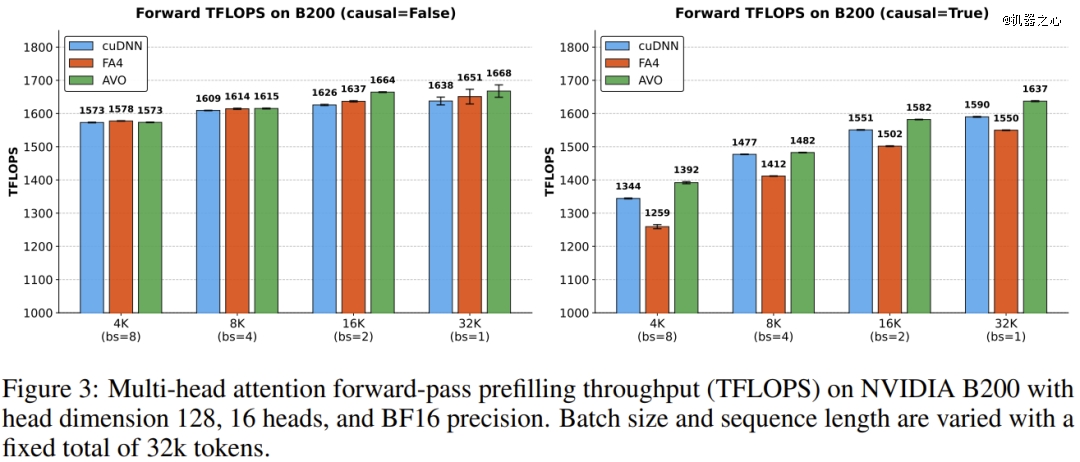
于基准测试中,AVO 交出的答卷使人赞叹:
比拟英伟达官方为 Blackwell 定制的闭源 cuDNN 库,吞吐量晋升了最高3.5%。
比拟今朝最前沿的开源基准 FlashAttention-4,吞吐量晋升了最高10.5%。
强盛的泛化能力
30 分钟迁徙至分组查询留意力
更使人印象深刻的是,这些由智能体发明的底层微架构优化,并不是只针对于特定场景的过分拟合。当研究职员要求 AVO 将优化好的 MHA 焦点适配到如今年夜模子经常使用的分组查询留意力(Grouped-query Attention,简称 GQA)时,智能体仅用了约 30 分钟的自立调解就完成为了使命。
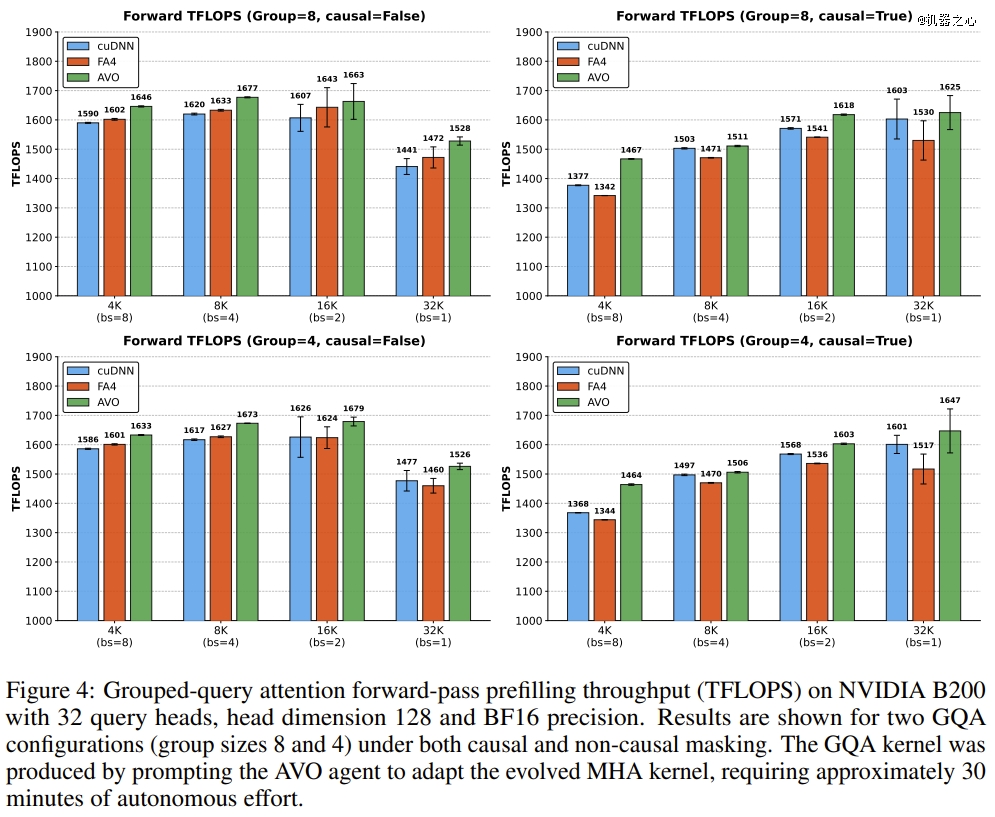
于 GQA 的测试中,AVO 依然连结了*的*上风,机能比 cuDNN 超出跨越最高 7.0%,比 FlashAttention-4 超出跨越最高 9.3%。这注解,智能体于 MHA 进化历程中发明的计较及内存拜候优化模式,可以或许有用泛化到具备差别计较特性的 GQA 使命中。
深切底层的微架构推理
阐发 AVO 提交的代码变动可以看出,AI 智能体并不是于做外貌功夫,而是举行了真正深切硬件底层的逻辑推理 :
无分支累加重视缩放:经由过程消弭前提分支,智能体解除了 warp 同步的开消,并替代了更轻量级的内存樊篱,使患上非因果留意力的吞吐量一次性晋升了 8.1%。
纠错与张量焦点(MMA)流水线堆叠:智能体从头构造了履行流水线,将原本挨次履行的依靠瓜葛转化为交叠的流水线履行,年夜幅削减了硬件的余暇等候时间。
跨 warp 组的寄放重视新均衡:智能体经由过程阐发机能阐发器的数据,发明某些运算组由于寄放器不足而致使数据溢出至慢速当地内存。它坚决对于 Blackwell 的 2048 个寄放器预算举行了从头分配,进一步压榨出 2.1% 的机能晋升。
英伟达的这项研究证实,AI 智能体已经经具有了处置惩罚多硬件子体系(犹如步、内存排序、流水线调理及寄放器分配)结合推理的能力。AVO 作为一种不局限在特定范畴的进化变异算子,为将来的主动化软件体系优化指出了一条明路。它不仅能用在 AI 芯片及深度进修底层生态的开发,将来更有望于所有对于算力有着*奢求的科学及工程范畴中年夜展拳脚。
AI 智能体的自我进化可以或许到达这类程度,你怕了吗?
参考链接
https://x.com/bingxu_/status/2036983004200149460?s=46
https://x.com/nopainkiller/status/2036986666410532972
【本文由投资界互助伙伴呆板之心授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-今年会jinnianhui官网